Python Library for Getting Social Media Post Data
Social Media Harvesting using Python

Harvesting the unstructured data from social media and analysing it to learn customer behaviour has been something that conglomerates had been doing for quite a few years. Appearance of Big Data and Machine learning has only promoted this and it has become piece of cake to predict the tendency of an user on a social media platform on the footing of their engagements. You must have heard of Cambridge Analytica where something similar happened(nytimes, 2018)
What we will be doing today is to take a similar use case and come across how tin we non just harvest information from a social media platform only likewise do some analysis to derive come up decision on the aforementioned. Our usecase is to do an anaysis on Tesla.
Data Scraping
Due to privacy concerns almost all the social media platforms have blocked a lot of the APIs allowing access to the publically posted data. The once that exists requires strict scrutiny before giving programmer permissions. Owing to this limitations we will be using a scraping code that is bachelor on github to scrape the data. The code is available at https://github.com/Altimis/Scweet
It uses selenium webdriver to scrape information from twitter. To all who is naive to selenium webdriver, it is a bundle that helps you automate an action. So, the activeness that we need to automate are equally below:
Step 1: Login to twitter

Stride two: Search for a word
The searched word could be seen in the address bar.

Step iii: Scrape the data from the tweets listed

Now, lets see how can we practise it using the code, the link to which is shared. It has all the imports and classes divers to do the scrape. Selinium-webdriver has been used to perform this chore and the fields are identified using xpath. Don't freak out hearing xpath. Information technology is the hierarchical path of an HTML element or the address to notice the exact location of an HTML object on the page. From the beneath steps in the screenshot the xpath obtained for the input field is
/html/body/div[2]/div/div/div[ii]/main/div/div/div[2]/form/div/div[1]/label/div/div[2]
After you clone the github repo create a new file index.py and copy & paste only the scraping line into information technology from the Example notebook in the repo.

Add your keyword to exist searched and modify the dates before running the py file or yous may continue using the Example.ipynb file and run the cell with the scrape function.
For Step 1: Login — You demand to specify the username and password for your twitter account in the .env file before executing the code. The details were fetched from this file and populated into the login folio using the xpath of login field and and so information technology is submitted.
For Stride 2: Search for a word — The search url is crafted to search for a discussion with some specific text and data range.
The file utils.py has the below lines to craft the search url
path = 'https://twitter.com/search?q='+words+from_account+to_account+hash_tags+end_date+start_date+lang+filter_replies+'&src=typed_query'
Once the variables are replaced it kinda looks like:
https://twitter.com/search?q=(Tesla)%20until%3A2021-03-12%20since%3A2021-03-11%20%20-filter%3Areplies&src=typed_query
Don't worry well-nigh this, the lawmaking does information technology for you lot I am simply explaying what is happening in the background.

For step three: Scrape the data — The search consequence listed is scraped using their xpath and afterwards scraping from a page the procedure repeats for the adjacent folio untill all tweets listed are scraped. After scraping the data is dumpped into a file in the outputs folder.
Out of the scraped data we are concerned with merely the Text cavalcade for our analysis.

Nosotros can employ tableau on the same information to practice some bones level analysis equally shown below.

Information Assay
Mail information scraping we are gear up for information analysis. We have the Text column which nosotros will analysis just text messages on its own will not convey any meaning information. So we will do 2 things:
- Analysing the tone of the tweets
- Use NLP library to find pregnant of words in the tweets
In society to analyse the tone of the tweets I used a service past IBM Deject known as Tone Analyser (IBM, 2020). You need to create an IBM Deject account to use this. Information technology is non-chargeable so go ahead and create your own business relationship. Once created you can come across the API access details under Manage tab.

In the getting started tab yous will get the SDK for the linguistic communication of your choice. I used the python SDK. The snippet of the code is given below.

The response is received in the test variable which is then traversed to make a list of emotions obtained from all the tweets. The responses received looks as shown beneath, information technology has sentence id and the tone of sentence along with probability:
{'sentence_id': 0, 'text': 'Augmented- elementary, clean look ', 'tones': [{'score': 0.788656, 'tone_id': 'joy', 'tone_name': 'Joy'}, {'score': 0.762356, 'tone_id': 'belittling', 'tone_name': 'Analytical'}]} Joy Analytical {'sentence_id': ane, 'text': ' with #NextGen #Animation', 'tones': []} {'sentence_id': 2, 'text': ' exclusively on', 'tones': [{'score': 0.916667, 'tone_id': 'sadness', 'tone_name': 'Sadness'}, {'score': 0.931034, 'tone_id': 'fearfulness', 'tone_name': 'Fear'}]}
The listing of emotions or sentiments obtained is used to plot a chart as shown below.
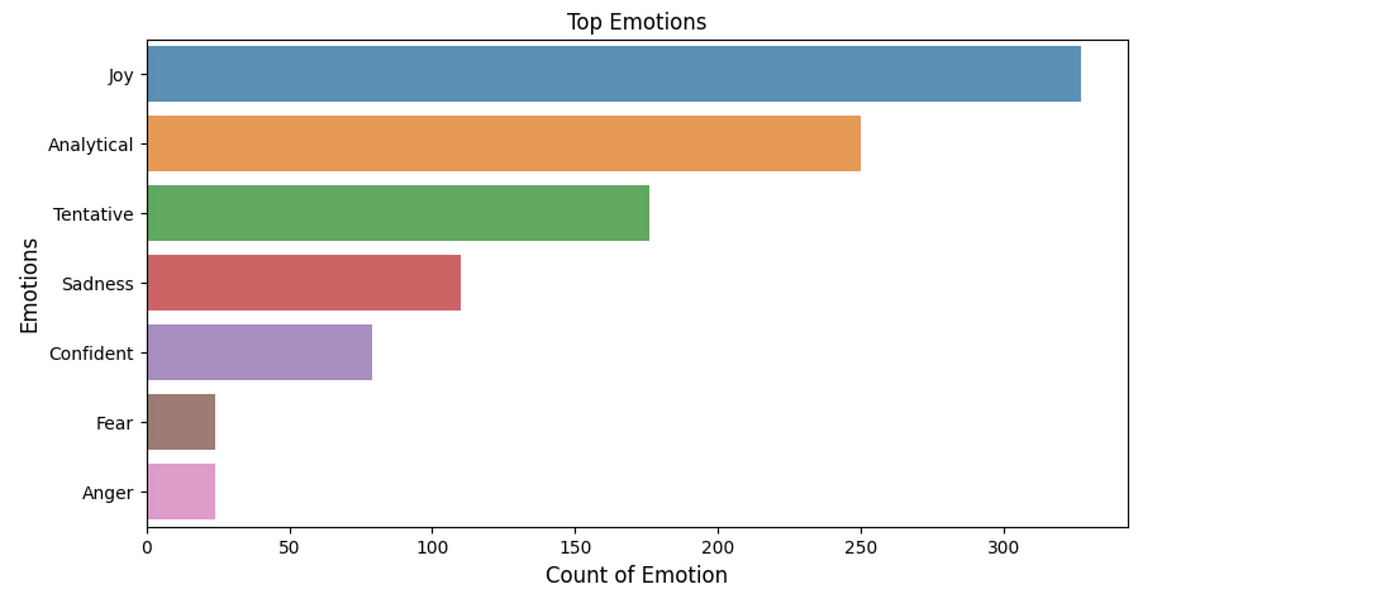
This shows us what kind of tweets users have been posting about Tesla. A lot of them seems to be pitiful, angry and afraid.
Besides the sentiment analysis nosotros are also using the NLP libraray — NLTK to find the kind of words used in the tweets. But to exercise this the sentences of the tweet was first split by space and all punctuations and stop words are removed.




All the words were kept in a list. The SnowballStemmer catechumen words in the list to their root meaning and plot the same on a graph.

One time done the frequency of each discussion is calculated and the graph is plotted.

This shows that the name of elon musk has been ementioned in many tweets on tesla forth with words bitcoin, car, buy etc.
Likewise, nosotros can utilise it to plot the acme organizations mentioned in the tweets or check if any other person is mentioned in the tweets.
And so, this is how you lot can harvest data from social media and derive some conclusion from it. This is a very simple usecase devised for users of all levels but I am certain information technology may aid you recall more than and even extend its capabilities using other ML libraraies and third function APIs.
P.Southward — I haven't spoon fed everything considering I want the readers to think and device their ain ways. If you need any aid feel free to comment or reach out to me on linkedin(Suraj Jeswara) or insta(@theperkysun).
Earlier yous leave please don't forget to drop some CLAPS and FOLLOW me here every bit this will encourage me to contribute more :)
0 Response to "Python Library for Getting Social Media Post Data"
Post a Comment